Tour d'horizon de la recherche plein texte avec PostgreSQL 12.
La recherche plein texte (ou full text searching ou text search aka ts) permet de trouver des documents contenant des termes de recherche.
Une recherche plein texte qui fonctionne bien consiste à construire des documents en modélisant des signaux afin d'améliorer la pertinence.
Modéliser les signaux consiste à répondre aux questions suivantes :
- comment est-ce que les utilisateurs ont l'intention de rechercher dans les champs du modèle source (souvent non optimisé pour la recherche) pour obtenir l'information désirée
- quel travail doit être effectué pour améliorer ou ajuster ces informations
Exemple de modélisation de signal : first_name / middle_name / last_name => full_name.
C'est pourquoi un document représente souvent une concaténation de champs, parfois stockés dans différentes tables ou obtenus dynamiquement.
Le process d'aller chercher des données ailleurs pour les rassembler dans un autre endroit est parfois qualifié d'ETL pour extract, transform et load. Le livre Relevant Search est plus spécifique et décrit le process de préparation à la recherche plein texte en 4 étapes :
- l'extraction consiste à récupérer les documents à partir de leurs sources
- l'enrichissement (optionnel) permet d'ajouter des informations utiles pour la pertinence (nettoyage, augmentation, fusion, etc.)
- l'analyse convertit les documents en structure exploitable par PostgreSQL
- l'indexation utilise des structures de données pour accélérer la recherche
Modèle vectoriel
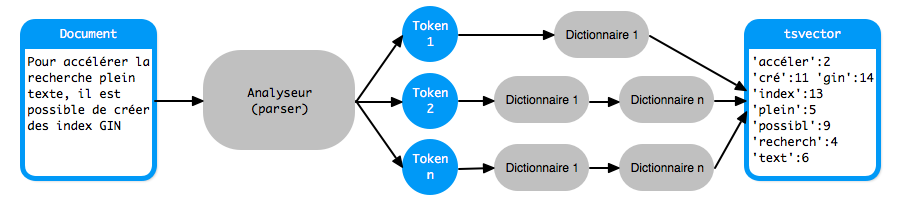
PostgreSQL utilise un modèle vectoriel. Un document est représenté par un vecteur dont chaque composante est un lexème (ou radical) accompagné de sa position et éventuellement d'un poids.
Une analyse est nécessaire pour passer d'un document à un vecteur pendant laquelle :
- le contenu d'un document est convertit en tokens grâce à un analyseur (parser)
- les tokens sont convertis en lexèmes grâce à un ensemble de dictionnaires
- les lexèmes sont stockés dans un vecteur
L'analyse est paramétrable via des configurations de recherche plein texte.
On passe toujours par cette phase d'analyse pour aller d'un document à un tsvector ou d'une requête à un tsquery :
to_tsvector
La fonction to_tsvector permet de convertir un document en vecteur.
Elle prend en entrée une configuration de recherche et le contenu d'un document puis retourne un tsvector :
=> SELECT to_tsvector('french', 'Pour accélérer la recherche plein texte, il est possible de créer des index GIN');
to_tsvector
--------------------------------------------------------------------------------------
'accéler':2 'cré':11 'gin':14 'index':13 'plein':5 'possibl':9 'recherch':4 'text':6
setweight permet d'attribuer un poids différent aux entrées d'un tsvector (A, B, C ou D) et peut être utilisé pour influencer le score des résultats.
=> SELECT setweight(to_tsvector('french', 'Salut'), 'A') || setweight(to_tsvector('french', 'Hello'), 'B');
?column?
-----------------------
'hello':2B 'salut':1A
to_tsquery
La fonction to_tsquery convertit un ou plusieurs termes de recherche séparés par des opérateurs en une requête de lexèmes permettant de rechercher dans des vecteurs.
Elle prend en entrée une configuration de recherche et un ou plusieurs termes de recherche séparés par des opérateurs puis retourne un tsquery :
SELECT to_tsquery('french', 'accélérer & plein & index');
to_tsquery
-------------------------------
'accéler' & 'plein' & 'index'
Les opérateurs disponibles sont :
&(AND)|(OR)!(NOT)<->(FOLLOWED BY)
Des poids peuvent être attachés à chaque lexème :
SELECT to_tsquery('french', 'accélérer:A & plein:B & index:AB');
to_tsquery
--------------------------------------
'accéler':A & 'plein':B & 'index':AB
* peut être attaché à un lexème pour rechercher un terme qui commence par la chaîne indiquée :
SELECT to_tsquery('french', 'acc:* & plein:*');
to_tsquery
---------------------
'acc':* & 'plein':*
to_tsquery permet de construire des requêtes compliquées au risque d'avoir un SQL invalide.
Il y a d'autres fonctions pour lesquelles il y a moins de risques d'erreurs, mais elles sont moins flexibles car ni les opérateurs, ni *, ni les poids ne sont pris en compte :
plainto_tsqueryproduit des lexèmes séparés automatiquement par l'opérateur&(AND)phraseto_tsqueryproduit des lexèmes séparés par l'opérateur<->sans écarter les termes courants : c'est utile pour rechercher des séquences exacteswebsearch_to_tsqueryconvertit une entrée brute fournie par un utilisateur (sans jamais lever d'erreurs de syntaxe) avec les règles suivantes :- le texte en dehors de guillemets est convertit en termes séparés par l'opérateur
& - le texte à l'intérieur de guillemets est convertit en termes séparés par l'opérateur
<-> ORest converti par l'opérateur|-est converti par l'opérateur!
- le texte en dehors de guillemets est convertit en termes séparés par l'opérateur
to_tsvector @@ to_tsquery
L'opérateur @@ retourne t (true) si un document correspond à une requête.
Il est possible de faire des recherches plein texte à la volée et sans index au prix d'un Seq Scan :
SELECT title FROM blog_post WHERE to_tsvector('french', title || ' ' || words) @@ to_tsquery('french', 'python | javascript');
Index GIN et GiST
Pour éviter le Seq Scan, PostgreSQL propose deux types d'index adaptés à la recherche plein texte.
Le premier est l'index GIN ou Generalized Inverted Index. Un index inversé est au cœur d'un moteur de recherche, c'est une des fondations de Lucene par exemple.
Le second est l'index GiST ou Generalized Search Tree.
Il y a beaucoup à dire sur ces index :
Pour savoir lequel choisir, je cite Egor Rogov :
As a rule, GIN beats GiST in accuracy and search speed. If the data is updated not frequently and fast search is needed, most likely GIN will be an option.
On the other hand, if the data is intensively updated, overhead costs of updating GIN may appear to be too large. In this case, we will have to compare both options and choose the one whose characteristics are better balanced.
La colonne à indexer doit être de type tsvector. Les tsvector doivent donc être stockés dans un champ de table et conservés à jour via une colonne générée ou des triggers.
Ajouter un score
Un score tente de mesurer la pertinence des documents afin de pouvoir les classer.
Le concept de pertinence est vague et doit s'adapter aux attentes implicites des utilisateurs. Par exemple, tout le monde s'attend à ce qu'une recherche dans les actualités fasse apparaître des articles récents sur les événements de dernière minute.
PostgreSQL dispose de deux fonctions de score prédéfinies :
ts_rank()qui calcule un score en se basant sur la fréquence des lexèmes correspondants à la recherchets_rank_cd()(cdpour cover density) similaire àts_rank()avec prise en compte de la proximité des lexèmes les uns par rapport aux autres (pour rechercher plutôt des phrases que des termes)
Si des poids ont été associés aux lexèmes, il est possible d'impacter leur score via l'argument weights. Si aucun poids n'est fourni, alors les valeurs par défaut sont utilisées dans l'ordre D, C, B et A :
{0.1, 0.2, 0.4, 1.0}
L'argument normalization précise si et comment la longueur du document doit impacter son score.
Analyse par configuration de recherche
Une bonne analyse des documents est l'étape la plus essentielle de la recherche plein texte.
L'analyse prend la forme d'une configuration de recherche composée d'un analyseur et de dictionnaires.
L'analyseur (parser) découpe un document en tokens. Il y a un seul analyseur dans PostgreSQL qui reconnait 23 types de tokens, avec parfois quelques surprises…
Chaque type de token obtenu est relié à un ou plusieurs dictionnaires. Chaque dictionnaire est consulté de gauche à droite afin d'obtenir un lexème.
Un dictionnaire est un programme qui accepte un token en entrée et retourne un tableau de lexèmes ou NULL si le token est reconnu comme un mot courant (ou stop word).
Si un dictionnaire est filtrant (par exemple unaccent), le token transformé continuera d'être passé aux dictionnaires suivant jusqu'à ce qu'un dictionnaire non filtrant puisse l'identifier comme un lexème utile ou non.
PostgreSQL dispose d'un certain nombre de configurations de recherche prédéfinies visibles via \dF.
default_text_search_config est la configuration par défaut :
SHOW default_text_search_config;
SET default_text_search_config TO 'french';
Il est possible pour une configuration donnée de voir quel analyseur et quels dictionnaires sont utilisés pour chaque token identifié via \dF+, par exemple : \dF+ french.
La fonction ts_debug permet d'inspecter la manière dont un document est transformé en tokens puis en lexèmes pour une configuration de recherche donnée :
=> SELECT * FROM ts_debug('french', 'Pour accélérer la recherche plein texte, il est possible de créer des index GIN');
Configuration de recherche personnalisée
On peut créer une configuration de recherche personnalisée avec CREATE TEXT SEARCH CONFIGURATION :
- soit à partir d'un parser (si la génération de tokens par défaut ne convient pas, vous avez la possibilité d'écrire ou d'utiliser un parser personnalisé)
- soit en copiant une configuration déjà existante.
Afin de normaliser les tokens en vue d'obtenir des lexèmes, toute la chaîne des dictionnaires est configurable. Des dictionnaires peuvent être créés grâce à des templates :
- dictionnaire simple
- dictionnaire des synonymes
- dictionnaire thésaurus
- dictionnaire Ispell (non inclus) avec support des formats Ispell, MySpell et Hunspell
- dictionnaire Snowball (inclus) permettant la racinisation (ou stemming)
unaccent
L'extension unaccent est un dictionnaire filtrant permettant de ne pas tenir compte des accents grâce à des règles.
La configuration french par défaut tient compte des accents, or c'est souvent l'inverse que l'on souhaite.
L'idée est donc de modifier la configuration existante :
DROP TEXT SEARCH CONFIGURATION IF EXISTS french_custom;
CREATE TEXT SEARCH CONFIGURATION french_custom ( COPY=french );
Les dictionnaires utilisés par les types de tokens renvoyés par le parser sont :
\dF+ french_custom
Il est possible de supprimer des types de tokens dont on n'aurait pas l'utilité :
ALTER TEXT SEARCH CONFIGURATION french_custom
DROP MAPPING FOR email, sfloat, float, int, uint;
Et de modifier la chaîne des dictionnaires :
CREATE EXTENSION IF NOT EXISTS unaccent;
ALTER TEXT SEARCH CONFIGURATION french_custom
ALTER MAPPING FOR hword, hword_part, word WITH unaccent, french_stem;
Synonymes
Un dictionnaire des synonymes fait correspondre un mot à un autre.
La syntaxe basique du fichier de configuration des synonymes est moins sexy que celle de Lucene.
Cependant, l'extension dict_xsyn permet une syntaxe plus compacte et permet de rechercher un mot en utilisant n'importe lequel de ses synonymes via un fichier de règles. Ce fichier de règles doit se terminer par .rules (mais cette extension ne doit pas figurer dans le paramètre RULES) et se situer physiquement dans $SHAREDIR/tsearch_data/ :
sudo bash -c 'cat <<EOT > `pg_config --sharedir`/tsearch_data/french_custom.rules
html markup balisage
javascript js
css styles
jeux vidéoludique game
empêcher interdire défendre éviter
EOT'
Avec ce fichier de règles nous pouvons créer un dictionnaire et l'intégrer dans la chaîne :
CREATE EXTENSION IF NOT EXISTS dict_xsyn;
CREATE TEXT SEARCH DICTIONARY french_custom_synonyms (TEMPLATE=xsyn_template, RULES=french_custom, MATCHSYNONYMS=true);
SELECT ts_lexize('french_custom_synonyms', 'html');
SELECT ts_lexize('french_custom_synonyms', 'js');
ALTER TEXT SEARCH CONFIGURATION french_custom
ALTER MAPPING FOR hword, hword_part, word
WITH french_custom_synonyms, unaccent, french_stem;
ALTER TEXT SEARCH CONFIGURATION french_custom
ALTER MAPPING FOR asciiword
WITH french_custom_synonyms, french_stem;
SELECT title FROM blog_post WHERE to_tsvector('french_custom', title) @@ to_tsquery('french_custom', 'interdire');
Thésaurus
Un dictionnaire thésaurus peut faire correspondre une phrase complète à une autre.
C'est assez puissant et ça évite le problème "sea biscuit" de Lucene.
Voici un exemple de fichier de configuration pour un thésaurus :
sudo bash -c 'cat <<EOT > `pg_config --sharedir`/tsearch_data/thesaurus_french_custom.ths
hypertext markup language : html
hypertext transfer protocol : http
cascading style sheets : css
transport layer security : tls
user datagram protocol : udp
transmission control protocol : tcp
appli Python : application web Python
EOT'
Il nous reste à créer un dictionnaire sur la base de cette configuration et à l'intégrer dans la chaîne :
CREATE TEXT SEARCH DICTIONARY thesaurus_french_custom (
TEMPLATE=thesaurus,
DictFile=thesaurus_french_custom,
Dictionary=simple
);
ALTER TEXT SEARCH CONFIGURATION french_custom
ALTER MAPPING FOR asciiword
WITH french_custom_synonyms, thesaurus_french_custom, simple;
select plainto_tsquery('french_custom','html');
select plainto_tsquery('french_custom','appli Python');
SELECT title FROM blog_post WHERE to_tsvector('french_custom', title) @@ plainto_tsquery('french_custom', 'appli Python');
Toute la difficulté des synonymes et des thésaurus repose dans la qualité des équivalences.
Si votre recherche est purement liée au langage, vous pouvez utiliser un équivalent WordNet en français, type WOLF ou WoNeF pour construire une liste de synonymes.
Si votre recherche doit être liée à votre domaine d'activité, il vous faudra du sur-mesure, ontologique !
Au rang des extensions très intéressantes il faut encore mentionner pg_trgm (trigram) et fuzzystrmatch.