Comprendre la cascade
Date de mise en ligne : 13 décembre 2004
Cet article est une adaptation en langue française (pas une traduction exacte) de l'article Understanding The Cascade
Article original par Holly 'n John ©positioniseverything
Cet article va décrire ce que signifie exactement "cascade", et pourquoi c'est si important lorsqu'on utilise des feuilles de style en cascade.
Rappel de la syntaxe CSS :
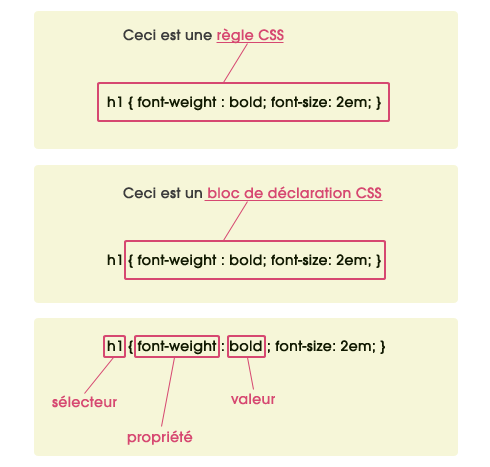
Que signifie exactement une "feuille de style"?
Une "feuille de style" est un jeu de règles de styles. La syntaxe utilisée aujourd'hui pour écrire des feuilles de style est CSS2.
CSS2 est un langage de feuille de style qui permet aux auteurs et aux lecteurs de lier du style (ex. les polices de caractères, l'espacement, les couleurs etc.) aux documents structurés (ex. documents HTML ou XHTML). En séparant la présentation du style du contenu des documents, CSS2 simplifie l'édition pour le Web et la maintenance d'un site.
La source d'un document (X)HTML est un bloc unique de code (tout du moins lorsqu'il atteint l'internaute), et n'importe quel nombre de feuilles de style peuvent lui être appliqué.
Les feuilles de style peuvent avoir des sources différentes :
- Une page web peut posséder une ou plusieurs feuilles de style écrites par son auteur.
- L'internaute peut avoir créé une "feuille de style utilisateur".
- Tous les navigateurs fonctionnent avec une feuille de style par défaut : "user agent style sheet".
Les feuilles de style peuvent donc avoir trois origines différentes : l'auteur (le webmaster par exemple), l'utilisateur (l'internaute) et l'agent utilisateur (le navigateur).
Dans les Feuilles de Style en Cascade niveau 2, la "cascade" décrit la façon dont ces diverses feuilles de style sont assemblées pour générer une unique feuille de style "virtuelle" qui utilise toutes les règles (implicitement déclarées ou non) de toutes ces différentes sources. Les CSS "cascadent", ou combinent toutes ces sources entre elles.
Chaque règle de style a un "sélecteur" qui indique au navigateur à quel élément s'applique la déclaration de style qui suit ce sélecteur.
Mais que se passe-t-il si par exemple plusieurs sélecteurs ciblent le même élément ? A ce moment là, on a plusieurs règles de style pour le même élément et elles entrent en conflit. C'est le sélecteur ayant le plus de poids qui gagne naturellement, surclassant les règles du sélecteur perdant.
La "cascade" décrit aussi la méthode par laquelle le "poids" est assigné à chaque sélecteur qui se trouve en situation de conflit.
Toutes les règles qui n'entrent pas en conflit avec d'autre règles sont automatiquement appliquées.
D'où viennent les feuilles de style ?
Les feuilles de style ont trois origines différentes : l'auteur, l'utilisateur et l'agent utilisateur.
Pour les auteurs :
- La feuille de style auteur peut être externe, c'est à dire contenue dans un fichier .css séparé, et appliquée au code (X)HTML soit via l'élément <link> ou en utilisant @import. Cette feuille de style peut être liée à n'importe quel nombre de pages (X)HTML, en conséquence le moindre changement effectué dans la feuille de style est appliqué à toutes les pages (X)HTML qui y font référence.
- La feuille de style auteur peut aussi être interne, il faut l'inclure dans des balises <style></style> dans l'en-tête de la page (X)HTML, et y placer les règles de style à l'intérieur.
- L'auteur peut aussi appliquer des styles "en-ligne" c'est à dire à l'intérieur des balises des éléments (X)HTML en tant qu'attribut de style, style="property: value;". Par exemple :
<p style="color: red;">Blablabla</p> - En plus, il peut aussi y avoir des règles de style qui n'ont rien à voir avec CSS dans le code HTML, comme les balises <font></font>. Si de telles règles sont présentes, elles doivent également être prises en compte par le navigateur.
Les utilisateurs ont leur mot à dire :
La plupart des navigateurs modernes supportent maintenant les "feuilles de style utilisateur", qui permettent aux utilisateurs (vous et moi) d'adapter leur propre expérience de surf en créant une feuille de style personnelle pour par exemple pallier des défaillances visuelles, ou simplement pour spécifier des styles en fonction de leurs goûts personnels. Il s'agit donc d'une feuille de style créée par l'internaute et appliquée à tous les sites qu'il va consulter via les préférences de son navigateur.
Cette possibilité n'est pas encore beaucoup exploitée, mais risque de devenir un facteur à prendre en compte lorsque les utilisateurs prendront conscience de cette possibilité offerte par les navigateurs récents.
L'agent utilisateur :
Enfin, tous les navigateurs disposent de styles appliqués par défaut à tous les éléments qui ne sont pas stylés par l'auteur ou l'utilisateur. Les spécifications du W3C montrent un exemple de feuille de style et encouragent les développeurs de navigateurs à l'utiliser en tant que feuille de style par défaut. Ces styles sont ceux qui sont appliqués si aucune autre feuille de style n'est appliquée à la page (X)HTML. En général, les fabriquants de navigateurs ont implémenté ces styles par défaut, à quelques nuances de gris près.
Assembler le tout
En conséquence, quand un navigateur parcourt un document (X)HTML, il recherche tous les fichiers CSS :
- Les fichiers CSS auteur externes liés via la balise <link> ou la règle @import
- Les styles auteur inclus dans l'en-tête du document (X)HTML via les balises <style></style>
- Les styles auteur « en-ligne » inclus dans les balises (X)HTML
- La feuille de style utilisateur
- La feuille de style par défaut du navigateur
Tout cela est stocké dans la mémoire du navigateur. Ayant tous ces styles en mémoire, le navigateur commence le processus de rendu graphique des éléments de la page.
Pendant ce processus, le navigateur vérifie si des déclarations de style ont des sélecteurs pointant l'élément (X)HTML en train d'être traité.
Exemple : le navigateur tombe sur un élément (X)HTML de type p et regarde dans les feuilles de styles si il existe un sélecteur p et des déclarations de style associées.
S'il trouve un sélecteur pour l'élément concerné, il applique les déclarations de style qui sont associés au sélecteur pointant l'élément en question.
Mais si à ce moment précis plusieurs déclarations de style sont assignées au même élément, elles entrent en conflit et la cascade entre en action et va déterminer quel style va être utilisé ou non. On entre dans le vif du sujet.
Le poids et l'origine
Quand tous les styles concernant un élément donné sont rassemblés, le navigateur doit résoudre les éventuels conflits entre les règles de style.
Normalement, les feuilles de style auteur surclassent les feuilles de style utilisateur, qui à leur tour surclassent les feuilles de style par défaut du navigateur.
Cela signifie par exemple que si une feuille de style utilisateur demande à ce que la couleur de fond de l'élément body soit rouge, mais que la feuille de style auteur définit la couleur de fond de body à vert, et bien la couleur de fond de body sera verte. Si ni la feuille de style auteur, ni la feuille de style utilisateur ne définissent de couleur de fond pour body, la feuille de style par défaut du navigateur prend le dessus et attribue à la couleur de fond de body une couleur blanche.
Le W3C a pensé que ces arrangements ne donnaient pas assez de pouvoir à l'utilisateur, en conséquence un mot-clef spécial a été inclus dans la spécification et permet à l'utilisateur de reprendre le contrôle des styles en surclassant les styles en provenance de l'auteur. Ce mot-clef est !important, et lorsqu'il est ajouté à la fin d'une déclaration de style utilisateur (avant le point-virgule), cette déclaration de style va surclasser un style auteur conflictuel, car elle sera considérée comme ayant plus de poids. Attendez que le public réalise ça ! Ci-dessous, un exemple de la façon dont ce mot-clef peut-être utilisé.
body { background-color: red !important; }!important peut également être utilisé dans les feuilles de style auteur, particulièrement lorsque plusieurs feuilles de style sont appelées par une page (X)HTML et que les styles sont potentiellement en conflit.
Dans CSS2, bien que les règles auteur battent les règles utilisateur, une règle utilisateur avec !important prendra toujours le dessus sur une règle auteur même avec !important. Il faut savoir que quand on en vient à !important, l'utilisateur a tous les pouvoirs !
La spécificité
Une fois que le poids et l'origine sont déterminés, mais qu'il y a encore des règles conflictuelles trouvées dans les styles auteur (styles externes, styles internes, ou styles en-ligne), les navigateurs doivent résoudre ces conflits. Ils font cela en évaluant la spécificité de chaque sélecteur des règles conflictuelles.
Les styles en conflit peuvent apparaître à la fois dans les feuilles de style auteur et utilisateur. Mais comme le tri par origine a déjà eu lieu, il n'y a jamais de tri par spécificité entre ces deux groupes.
Il y a beaucoup à dire sur les règles de spécificité, mais c'est plutôt compliqué alors commençons par éclairer les points basiques en premier et intéressons-nous à l'ordre des styles.
L'ordre
Si les conflits de style ne peuvent être résolus avec les méthodes précédentes, le résultat final du tri est dicté par l'ordre linéaire que le navigateur donne aux règles de style.
Généralement, quand 2 règles ou davantage sont équivalentes, celle lue en dernier gagne.
Mais qu'en est-il des styles importés ? Comment un navigateur détermine dans quel ordre les appliquer ? Et bien les styles @importés sont toujours appelées depuis une feuille de style externe ou interne, donc les styles @importés sont toujours traités comme partie intégrale de la feuille qui l'appelle.
D'après la spécification : La règle '@import' permet aux utilisateurs l'importation de règles de style à partir d'une autre feuille de style. Les règles @import doivent précéder toutes autres règles dans la feuille de style.
<style type="text/css">
@import url(extra.css);
body {color: blue; }
p {color: green; }
</style>Pour les feuilles de style auteur, l'ordre de lecture est le suivant :
- les fichiers externes sont lus en premier (dans l'ordre dans lequel ils sont appelés, en commençant par les styles @importés)
- ensuite les styles internes si on considère qu'ils sont déclarés après les styles externes (en commençant par les styles @importés s'il y en a)
- enfin les styles en-ligne sont lus en dernier
Cela signifie que les styles en-ligne prennent le dessus sur tous les autre styles sauf sur ceux qui ont le mot-clef !important.
Si une feuille de style externe est appellée après une feuille de style interne, alors les règles de la feuille de style externe prennent le dessus sur celles de la feuille interne. Ce qui compte réellement est l'ordre d'apparition des différentes feuilles de style auteur dans le code source (X)HTML.
La feuille de style par défaut du navigateur arrive toujours avant toutes les autres feuilles de style.
Quand le navigateur a lu toutes les feuilles de style et que 2 règles ou plus sont en conflit, celle lue en dernier par le navigateur gagne, en considérant que les poids sont égaux.
Résumé
La liste ci-dessous résume les méthodes utilisées par les navigateurs pour déterminer quelles déclarations de style doivent être appliquées à quel sélecteur.
- Rassemblement de toutes les règles concernant le sélecteur
- Tri des règles par origine et par importance (poids)
- Origine : !important, en-ligne, interne (en-tête), liée, importée, utilisateur, navigateur
- Importance : !important, auteur, utilisateur, navigateur
- Tri des règles par spécificité du sélecteur CSS. Les sélecteurs spécifiques vont prendre le dessus sur les sélecteurs plus généraux.
- Tri par ordre. Ayant la même origine, la même importance et la même spécificité, la règle déclarée en dernier (la plus proche de l'élément sélectionné) gagne.
La cascade est assez logique. Le seul point difficile est cette « spécificité ». Il est temps de se préparer pour un voyage dans la jungle de la spécificité. Hé, vous, dans le fond de la classe ! Soyez attentifs !
D'abord, quelques explications
Avant d'entrer dans les détails de la spécificité, faisons un tour des termes utilisés dans cette section.
Les classes et les ID sont des manières similaires d'assigner des règles de style à n'importe quel élément, simplement en spécifiant en tant qu'attribut de la balise ouvrante de l'élément (X)HTML concerné le nom de la classe ou de l'ID.
Dans la feuille de style, la syntaxe est la suivante : .nomclasse { propriété : valeur ; } et #nomid { propriété : valeur ; }.
En (X)HTML un div avec un attribut class ressemble à : <div class=“nomclasse“>contenu</div>. Un div avec un attribut id ressemble à : <div id=“nomid“>contenu</div>.
Note : Les ID fonctionnent comme les classes en CSS, mais le même ID est supposé être utilisé une et une seule fois par page, tandis qu'une même classe peut être utilisée autant de fois que vous le souhaitez sur la même page. Les ID sont aussi utilisés par les langages de script comme Javascript, et dans ce cas, il vaut mieux qu'ils ne soient utilisés qu'une fois sinon une erreur se produira. Prenez l'habitude de n'utiliser le même ID qu'une seule fois par page. En revanche il peut y avoir plusieurs ID mais avec des noms différents sur la même page.
Les attributs sont les choses variées qui sont ajoutées aux balises ouvrantes des éléments (X)HTML, les classes et les ID sont des attributs. Exemples d'attributs href="www.funkykode.com", et alt="photo description" parmi beaucoup d'autres.
Un sélecteur d'attribut CSS ressemble à table[align] { color: blue ; }. Remarquez les crochets qui entourent le nom de l'attribut. Ce sélecteur rendrait bleu le texte de toutes les tables qui auraient l'attribut align. Si vous donnez une valeur à votre attribut, table[align="center"] {color:blue ;} il deviendrait encore plus spécifique et serait applicable seulement aux tables avec une valeur d'attribut égale à center. Tristement, Microsoft n'a pas encore développé de navigateur supportant ce type de sélecteur.
Il y a beaucoup d'autres attributs, mais la plupart des attributs de présentation ont maintenant des équivalents CSS, et sont considérés comme dépréciés par le W3C (pour de très bonnes raisons). Un bon codeur devrait prendre l'habitude d'utiliser CSS le plus souvent possible, parce que cela rend la maintenance d'un site plus facile.
Les noms des éléments peuvent être utilisés comme des sélecteurs CSS. Par exemple “p“, “body“ et “table“ (appelés “sélecteurs de type“ par le W3C). Un sélecteur d'élément simple a juste un nom d'élément, suivi par un bloc de déclaration de style. Exemple : p { color: lime ; } pour la couleur de texte dans un paragraphe.
Un combinateur dit au navigateur de combiner 2 ou davantage de sélecteurs pour localiser un élément et lui appliquer des styles.
Un combinateur descendant est un espace qui sépare 2 (ou plus) sélecteurs simples comme des noms d'éléments, des classes, etc. L'ordre dans lequel ces simples sélecteurs apparaissent détermine quel élément est pointé. Les classes, les ID, les sélecteur d'attributs et les pseudo-classes peuvent être combinés avec le combinateur descendant.
Deux autres façons de combiner des sélecteurs simples sont d'utiliser les caractères ">" (sélecteur d'enfant) et "+" (sélecteur d'enfants adjacents). Bien que Internet Explorer Windows supporte les combinateurs descendants, il ne supporte pas les sélecteurs d'enfant et les sélecteurs d'enfants adjacents. Cependant, IE5 pour Mac les supporte.
Pour tout savoir sur les sélecteurs : http://www.yoyodesign.org/doc/w3c/css2/selector.html
La spécificité par les nombres
La spécificité est une des spécifications basiques de CSS. Il s'agit d'une méthode pour déterminer quels sélecteurs sont plus spécifiques que les autres et donc de déterminer quelle règle sera appliquée à un élément donné. Le W3C a défini un système numérique pour calculer la spécificité d'un sélecteur. En CSS2, ce système consiste en 3 nombres [a, b, c], et tout comme le bon vieux système décimal, les nombres les plus importants sont à gauche, alors que les moins importants sont à droite. Les nombres sont calculés comme cela :
- Compter le nombre d'attributs ID dans le sélecteur (a). Les sélecteurs sont considérés comme davantage spécifiques quand ils contiennent des ID. Chaque ID dans un sélecteur incrémente le nombre de gauche (a) de 1.
- Compter le nombre des autres attributs et pseudo-classes dans le sélecteur (b). Pour chaque attribut qui n'est pas un ID et pour chaque pseudo-classe, le nombre du milieu (b) est incrémenté de 1. Note : une classe CSS est un attribut aussi.
- Compter le nombre de noms d'éléments dans le sélecteur (c). Le nombre le plus à droite (c) est incrémenté de 1 pour chaque nom d'élément / type trouvé dans le sélecteur.
Après cela, trois valeurs [a, b, c] ont été établies, elles sont alors concaténées pour déterminer la spécificité d'un sélecteur.
Attention : le système numérique pour déterminer la spécificité n'est pas un système numérique en base 10. Le W3C spécifie que les valeurs [a, b, c] doivent être concaténées.
Les noms des éléments
Un sélecteur élément unique, comme p { color: red ; } aura cette spécificité : [0,0,1]. Si un sélecteur descendant comme table p { color: green ; } apparaît dans la même feuille de style, ce sélecteur aura la spécificité de [0,0,2] parce qu'il a deux noms d'éléments dans le sélecteur, et surclassera le premier, en rendant le texte vert.
Pensez-y, ce sélecteur descendant cible tous les paragraphes contenus n'importe où dans un élément table, et c'est beaucoup plus spécifique que juste un paragraphe dans la page. Donc les sélecteurs les plus spécifiques devraient prendre le dessus sur les sélecteurs moins spécifiques, et bien sûr ça se passe comme ça. C'est la même chose pour les sélecteurs utilisant une variété de combinateurs (les combinateurs sont : les blancs et les caractères ">" et "+"). Ce qui compte c'est le nombre de noms d'éléments qui apparaissent dans le sélecteur, et rien d'autre.
Donc avec deux sélecteurs qui sont des noms d'éléments et qui pointent la même cible, celui qui contient le plus de noms d'éléments prendra le dessus. Cela est vrai seulement si les sélecteurs ne contiennent que des noms d'éléments.
Il existe un sélecteur universel, noté * (étoile), qui est vérifié pour le nom de n'importe quel type d'élément. Il sélectionne tous les éléments, mais utilisé comme partie d'un sélecteur complexe, il devrait pointer seulement certains éléments en fonction de la construction du sélecteur. Ainsi, si vous avez un élément avec une classe « foo », et que vous souhaitez appliquer un style à tous les éléments inclus dans votre élément qui a la classe « foo » (et ce, quel que soit le niveau d'imbrication), écrivez .foo * { propriété : valeur ; }. Maintenant, tous les éléments inclus dans l'élément qui a la classe « foo » auront ce style.
.foo * * { propriété : valeur ; } (notez les 2 sélecteurs universels : * *) va sélectionner tous les éléments inclus dans des éléments qui sont eux-même inclus dans « .foo ». Ainsi, un enfant descendant directement de .foo ne sera pas sélectionné.
Même si le sélecteur universel sélectionne tous les éléments, il n'est pas lui même un élément “type“. Il n'est pas compté comme un élément et n'incrémente pas la spécificité du nombre le plus à droite (c). Le sélecteur universel a une spécificité de “0“ : [0,0,0].
Les attributs et les pseudo-classes
Si un sélecteur contient des attributs et/ou des pseudo-classes, ils sont comptés, et le nombre pris en compte est le nombre du milieu (b). Souvenez vous, les classes sont comptées comme des attributs. Les pseudo-classes comprennent les sélecteurs les plus utilisés comme :hover, et :first-child.
Les ID
Puisque les ID sont utilisés une seule fois par page, il est difficile d'obtenir plus spécifique que ça. Par conséquent les ID obtiennent le plus de poids sur l'échelle de la spécificité. Chaque ID dans un sélecteur augmente le nombre le plus à gauche de 1, et si un autre sélecteur n'a pas d'ID, il perdra et ce quelque soit le nombre de classes, d'attributs, de noms d'éléments… qu'il a. Un seul ID en tant que sélecteur aura cette spécificité [1,0,0]. Les ID ont toujours le poids le plus important lorsqu'il est question de spécificité.
Exemples
Regardons quelques exemples :
em.hilite { background-color: yellow ; }
div p em { background-color: green ; }Supposons que nous ayons du texte en emphase avec une classe “hilite“, à l'intérieur d'un paragraphe qui lui-même est dans un div. Nous avons vu avant que si 2 sélecteurs ont la même importance, origine et spécificité, celui lu en dernier sera appliqué. Ici, les 2 sélecteurs ci-dessus pointent le même élément : notre texte en emphase. Alors, lequel “gagne“ ?
On peut penser que la dernière règle sera appliquée, parce qu'elle vient après, mais dans ce cas, les deux règles doivent avoir la même spécificité, et dans notre exemple, elles ne l'ont pas. Le premier sélecteur a la plus grande spécificité. Calculons la spécificité :
em.hilite { background-color: yellow ; } [0,1,1]
div p em { background-color: green ; } [0,0,3]Le code ci-dessus nous montre que le sélecteur em.hilite a ID : a=0, attributs/pseudo-classes : b=1, et éléments : c=1, soit [0,1,1], tandis que le sélecteur div p em a ID : a=0, attributs/pseudo-classes : b=0, et éléments : c=3, soit [0,0,3]. Il est clair que le sélecteur [0,1,1] gagne sur le sélecteur [0,0,3] mais dans le système amusant de la spécificité, [0,1,1] va aussi battre [0,0,12] !
Quoi ? 11 bat 12 ? Tu rigoles ! Non, on ne plaisante pas, et ce premier nombre n'est pas réellement 11. Souvenez-vous, on n'est pas dans un système en “base 10“. Dans le système de la spécificité, tout nombre positionné le plus à gauche bat n'importe quelle valeur de droite. Donc, dans notre exemple le sélecteur [0,1,1] a une plus grande spécificité que [0,0,12] en vertu du 1 au milieu.
Retournons à notre exemple de texte en emphase. Nous allons faire un petit changement et calculer la spécificité.
em.hilite { background-color: yellow ; } [0,1,1]
div p em.hilite { background-color: green ; } [0,1,3]Le second sélecteur va maintenant gagner car il est plus spécifique. Même si on change l'ordre des règles, le texte en emphase aura une couleur de fond verte.
La spécificité et les styles en-ligne
Dans CSS 2, on donne aux styles en-ligne le poids (spécificité) d'un ID unique d'après le W3C. Donc en théorie, un sélecteur plus spécifique peut l'emporter sur un attribut de style en-ligne (style= “propriété : valeur ;“). En réalité, les navigateurs donnent au règles contenues dans des attributs style une spécificité de [1,0,0,0], ajoutant un quatrième niveau de spécificité, et de cette façon les styles en-ligne gagnent toujours sur les autres règles.
Dans CSS 2.1, on donne à l'attribut “style“ la valeur “a=1“ et il y a maintenant 4 nombres à concaténer, [a,b,c,d]. L'idée est que si vous, en tant qu'auteur, écrivez un style en-ligne, c'est manifestement ce que vous voulez appliquer à cet élément spécifique.
Les trucs de présentation autre que CSS
CSS n'est pas la seule façon de styler les éléments. Il y a la bonne vieille (ou mauvaise vieille) balise <font>, et divers attributs qui peuvent être ajoutés aux balises d'élément. Par exemple “align“ ou “border“. Ces attributs de style peuvent être appliqués à un élément comme des règles CSS, mais ont une spécificité de [0,0,0] et sont traités comme s'ils se trouvaient au début de la feuille de style auteur. Cela permet à n'importe quel style auteur pointant le même élément de prendre le dessus sur de tels attributs.
Le W3C suggère de ne pas utiliser de style autre que CSS lorsqu'on crée des documents XHTML ou XML. Soyez conscient qu'il y a un grand nombre d'attributs qui ne sont pas considérés comme des attributs de présentation, dont “colspan“, “label“, “href“, “onload“, et même “style“.
L'élément <font> lui même peut être stylé avec CSS, donc un vieux site contenant beaucoup de balises <font> peut être modernisé sans avoir à chercher et à remplacer des centaines de balises <font>.
font {
color: red;
font-size: 1em;
font-family: sans-serif;
}Résumer la spécificité
Premièrement, compter le nombre d'ID. Si le nombre d'ID est égal, compter le nombre d'attributs, classes et pseudo-classes. Si leur nombre est égal, compter le nombre de noms d'éléments. Si leur nombre est égal, la cascade prend le pouvoir, et laisse gagner la dernière règle lue par le navigateur.
Essayez par vous-même
Maintenant que vous avez compris comment fonctionne la spécificité, peut-être voudriez-vous mettre en pratique ce que vous avez appris grâce à un test ? Vous avez de la chance car on a un test pour vous ! Ci-dessous vous trouverez un bloc de code avec des sélecteurs. Chaque sélecteur est sur une nouvelle ligne. Votre travail est de déterminer la spécificité des sélecteurs.
*
div
div p
.myclass
ol.myclass li
#main
div#main
ul li ul li.sub
table[align] td
html body div div table tr td p strong
h1 + *[rel="up"]
ul ol+li
p.myclass.alignright
div#main>p.myclass
<font>
style="color: lime" (pensez à CSS 2.1)
Ici se trouve la page des réponses sur positioniseverything.net. Bonne chance.